PaddleSpeech TTS 接入 HomeAssistant
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,提供 TTS 与 ASR 能力
本文将介绍 PaddleSpeech 的安装及如何接入 HomeAssistant,最终实现在 HA 中进行 TTS 语音播报。
1 安装 PaddleSpeech
完整教程请参考官方教程: https://github.com/PaddlePaddle/PaddleSpeech
本文将介绍使用 docker 镜像进行部署。
1.1 检查 GPU 驱动

使用 nvidia-smi 检查 GPU 驱动是否正常。正常情况下,命令会输入类似上图的信息,会有温度、显存等信息展示。
1.2 部署 docker 镜像
docker run -d --name paddlespeech \
--runtime=nvidia \
-v $PWD/paddlespeech_data:/mnt \
-p 8888:8888 \
paddlecloud/paddlespeech:develop-gpu-cuda10.2-cudnn7-fb4d25 paddlespeech_server start
paddlespeech 启动成功后,观察 nvidia-smi 命令输出,可以看到目前占用了 2.6G 显存。
1.3 测试 PaddleSpeech
使用工具进行 paddlespeech api 测试。
curl --location 'http://localhost:8888/paddlespeech/tts' \
--header 'Content-Type: application/json' \
--data '{
"text": "今天天气不错"
}'会返回如下的 json 响应。注意 audio 字段实际非常长,本处作了截断处理。
{
"success": true,
"code": 200,
"message": {
"description": "success."
},
"result": {
"lang": "zh",
"spk_id": 0,
"speed": 1.0,
"volume": 1.0,
"sample_rate": 24000,
"duration": 1.2875,
"save_path": null,
"audio": "UklGRgLjAQBXQVZFZm10I...MBTuQ=="
}
}响应耗时为 200ms 左右。
至此,paddlespeech 服务运行成功,接下来接入 homeassistant。
2. 接入 HomeAssistant
2.1 HACS 添加插件
在 HomeAssistant HACS 自定义存储库中添加 https://github.com/idreamshen/hass-paddlespeech 并重启 HA

2.2 HA 添加集成
在 HA 集成中搜索 paddlespeech,点击进入配置页面。

2.3 配置集成
输入 TTS 的地址,比如:http://192.168.1.200:8888
192.168.1.200 需要更换为 paddlespeech 的实际 ip。

稍等片刻,在设备中就能找到新创建的 TTS 实体

2.4 TTS 播报测试
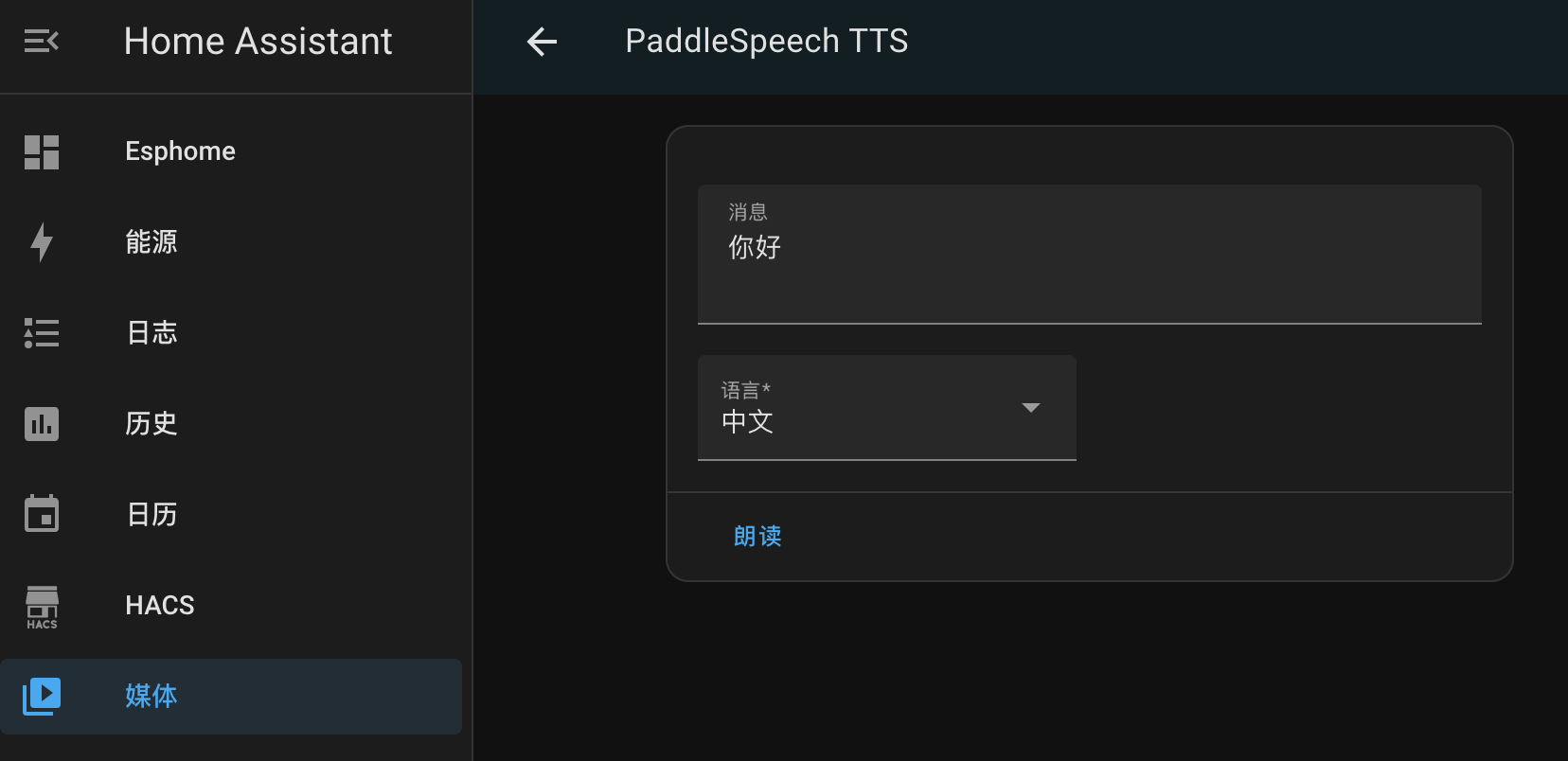
HA导航,选择媒体 - PaddleSpeech TTS。在消息中填入期望的文本,然后点击“朗读”即可验证 TTS 播报是否正常。
2.5 HA 自动化

- 动作:选择 Text-to-speech
- 目标:选择 PaddleSpeech
- 媒体播放器实体:选择自己的播放器
- 消息:填写实际文本内容